





Одной из наиболее важных сфер применения первых СУБД было планирование производства для компаний, занимающихся выпуском продукции. Например, если автомобильная компания хотела выпустить 10 000 машин одной модели и 5000 - другой, ей необходимо было знать, сколько деталей следует заказать у своих поставщиков. Чтобы ответить на этот вопрос, необходимо определить, из каких деталей состоят эти части и т.д. Например, машина состоит из двигателя, корпуса и ходовой части; двигатель в свою очередь состоит из клапанов, цилиндров, свеч и т.д. Работа со списками составных частей была как будто специально предназначена для компьютеров. Список составных частей изделия по своей природе является иерархической структурой. Для хранения данных, имеющих такую структуру, была разработана иерархическая модель данных, которую иллюстрирует рис. 72.
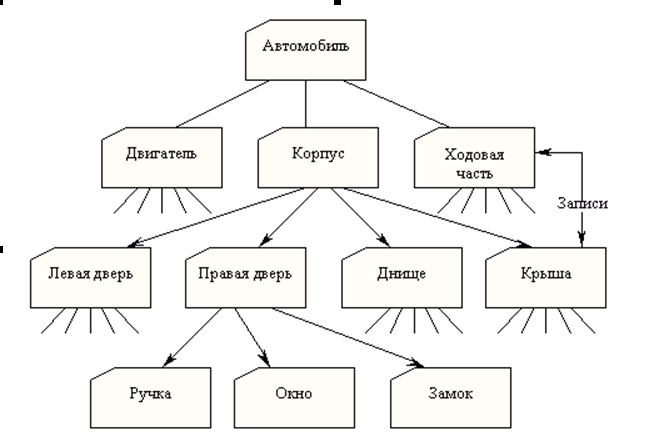
Рисунок 72 Иерархическая база данных, содержащая информацию о составных частях
В этой модели каждая запись базы данных представляла конкретную деталь. Между записями существовали отношения предок/потомок, связывающие каждую часть с деталями, входящими в неё.
Чтобы получить доступ к данным, содержащимся в базе данных, программа могла:
· найти конкретную деталь (правую дверь) по её номеру;
· перейти "вниз" к первому потомку (ручка двери);
· перейти "вверх" к предку (корпус);
· перейти "в сторону" к другому потомку (правая дверь).
Таким образом, для чтения данных из иерархической базы данных требовалось перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону.
Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) компании IBM, появившаяся в 1968 году. Ниже перечислены преимущества IMS и реализованной в ней иерархической модели.
· Простота модели. Принцип построения IMS был легок для понимания. Иерархия базы данных напоминала структуру компании или генеалогическое дерево.
· Использование отношений предок/потомок. СУБД IMS позволяла легко представлять отношения предок/потомок, например: "А является частью В" или "А владеет В".
· Быстродействие. В СУБД IMS отношения предок/потомок были реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске рядом друг с другом, что позволяло свести к минимуму количество операций записи-чтения.
Если структура данных оказывалась сложнее, чем обычная иерархия, простота структуры иерархической базы данных становилась её недостатком. Например, в базе данных для хранения заказов один заказ мог участвовать в трёх различных отношениях предок/потомок, связывающих заказ с клиентом, разместившим его, со служащим, принявшим его, и с заказанным товаром.
Такие структуры данных не соответствовали строгой иерархии IMS. В связи с этим для таких приложений, как обработка заказов, была разработана новая сетевая модель данных. Она являлась улучшенной иерархическоймоделью, в которой одна запись могла участвовать в нескольких отношениях предок/потомок, как показано на рис. 73.
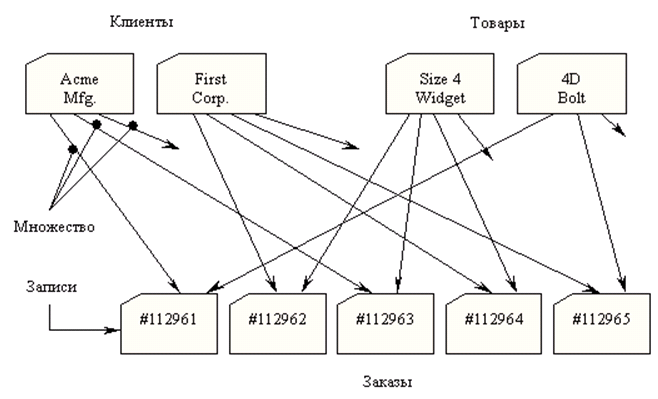
Рисунок 73. Сетевая база данных, содержащая информацию
о заказах
В сетевой модели такие отношения назывались множествами. Сетевые базы данных обладали рядом преимуществ:
· Гибкость. Множественные отношения предок/потомок позволяли сетевой базе данных хранить данные, структура которых была сложнее простой иерархии.
· Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигали быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений.
Конечно, у сетевых баз данных были недостатки. Как и иерархические, сетевые базы данных были очень жесткими. Наборы отношений и структуру записей приходилось задавать наперёд. Изменение структуры базы данных обычно означало перестройку всей базы данных.
Как иерархическая, так и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос типа "Какой товар наиболее часто заказывает компания Acme Manufacturing?", программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной.
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. На рисунке 74 показана реляционная версия сетевой базы данных, содержащей информацию о заказах и приведенной на рис. 73.

Рисунок 74 - Реляционная база данных, содержащая информацию
о заказах
Реляционной называется база данных, в которой все данные, доступные пользователю, организованы в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
Приведенное определение не оставляет места встроенным указателям, имеющимся в иерархических и сетевых СУБД. Несмотря на это, реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
В реляционной базе данных информация организована в виде таблиц, разделённых на строки и столбцы, на пересечении которых содержатся значения данных. У каждой таблицы имеется уникальное имя, описывающее её содержимое. Более наглядно структуру таблицы иллюстрирует рис. 75, где изображена таблица OFFICES.
Каждая горизонтальная строка этой таблицы представляет отдельную физическую сущность - один офис. Пять строк таблицы вместе представляют все пять офисов компании. Все данные, содержащиеся в конкретной строке таблицы, относятся к офису, который описывается этой строкой.
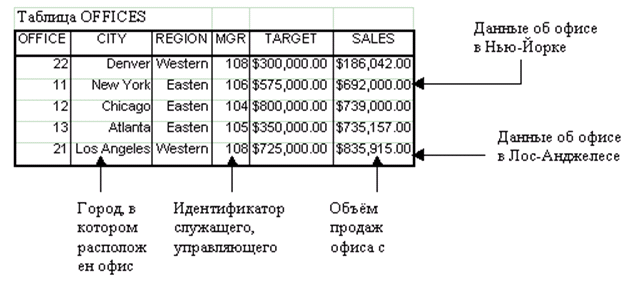
Рисунок 75. Структура реляционной таблицы
Каждый вертикальный столбец таблицы OFFICES представляет один элемент данных для каждого из офисов. Например, в столбце CITY содержатся названия городов, в которых расположены офисы. В столбце SALES содержатся объёмы продаж, обеспечиваемые офисами.
На пересечении каждой строки с каждым столбцом таблицы содержится в точности одно значение данных. Например, в строке, представляющей нью-йоркский офис, в столбце CITY содержится значение "New York". В столбце SALES той же строки содержится значение $692.000.000, которое является объёмом продаж нью-йоркского офиса с начала года.
Все значения, содержащиеся в одном и том же столбце, являются данными одного типа. Например, в столбце CITY содержатся только слова, в столбце SALES денежные суммы, а в столбце MGR целые числа, представляющие идентификаторы служащих. Множество значений, которое может содержаться в столбце, называется доменом этого столбца. Доменом столбца CITY является множество названий городов. Доменом столбца SALES является любая денежная сумма. Домен столбца REGION состоит всего из двух значений, "Eastern" и "Western", поскольку у компании всего два торговых региона.
У каждого столбца в таблице есть своё имя, которое обычно служит заголовком столбца. Все столбцы в одной таблице должны иметь уникальные имена, однако разрешается присваивать одинаковые имена столбцам, расположенным в различных таблицах. На практике такие имена столбцов, как NAME, ADDRESS, QTY, PRICE и SALES часто встречаются в различных таблицах одной базы данных.
Столбцы таблицы упорядочены слева направо, и их порядок определяется при создании таблицы. В любой таблице всегда есть как минимум один столбец.
В отличие от столбцов, строки таблицы не имеют определённого порядка. Это значит, что если последовательно выполнить два одинаковых запроса для отображения содержимого таблицы, нет гарантии, что оба раза строки будут перечислены в одном и том же порядке.
В таблице может содержаться любое количество строк. Вполне допустимо существование таблицы с нулевым количеством строк. В таком случае она называется пустой. Пустая таблица сохраняет структуру, определённую её столбцами, просто в ней не содержится данные.
Первичные ключи
Поскольку строки в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру в таблице. Здесь "первой", "последней" или "тринадцатой" строки. Тогда каким же образом можно указать в таблице конкретную строку, например строку для офиса, расположенного в Денвере?
В правильно построенной реляционной базе данных в каждой таблице есть один или несколько столбцов, значения в которых во всех строках разные. Этот столбец (столбцы) называется первичным ключом таблицы. Для иллюстрации можно посмотреть на базу данных, показанную на рис. 75. На первый взгляд, первичным ключом таблицы OFFICES могут служить и столбец OFFICE, и столбец CITY. Однако в случае, если компания будет расширяться и откроет в каком-либо городе второй офис, столбец CITY больше не сможет выполнять роль первичного ключа. На практике в качестве первичных ключей таблиц обычно следует выбирать идентификаторы, такие как идентификатор офиса (OFFICE в таблице OFFICES), служащего (EMPL_NUM в таблице SALESREPS) и клиента (CUST_NUM в таблице CUSTOMES). А в случае; с таблицей ORDERS выбора нет - единственным столбцом, содержащим уникальные значения, является номер заказа (ORDER_NUM).

Рисунок 76. Пример таблицы с составным первичным ключом
Таблица PRODUCTS, фрагмент которой показан на рисунке 76, является примером таблицы, в которой первичный ключ представляет собой комбинацию столбцов. Такой первичный ключ называется составным. Столбец MRF_ID содержит идентификаторы производителей всех товаров, перечисленных в таблице, а столбец PRODUCT_ID содержит номера, присвоенные товарам производителями. Может показаться, что столбец PRODUCT_ID мог бы и один выполнять роль первичного ключа, однако ничто не мешает двум различным производителям присвоить своим изделиям одинаковые номера. Таким образом, в качестве первичного ключа таблицы PRODUCTS необходимо использовать комбинацию столбцов MRF_ID и PRODUCT_ID. Для каждого из товаров, содержащихся в таблице, комбинация значений в этих столбцах будет уникальной.
Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. Таблица, в которой все строки отличаются друг от друга, в математических терминах называется отношением. Именно этому термину реляционные базы данных и обязаны своим названием, поскольку в их основе лежат отношения (таблицы с отличающимися друг от друга строками).
Отношения предок/потомок (один-ко-многим).
Одним из отличий реляционной модели от первых моделей представления данных было то, что в ней отсутствовали явные указатели, используемые для реализации отношений предок/потомок в иерархической модели данных. Однако вполне очевидно, что отношения предок/потомок существуют и в реляционных базах данных. Например, в базе данных, показанной на рисунке 78, каждый из служащих закреплен за конкретным офисом, поэтому ясно, что между строками таблицы OFFICES и таблицы SALESREPS существует отношение. Не приводит ли отсутствие явных указателей в реляционной модели к потере информации?
Как следует из рисунка 77, ответ на этот вопрос должен быть отрицательным. На рисунке изображено несколько строк из таблиц OFFICES и SALESREPS. Необходимо обратить внимание на то, что в столбце REP_OFFICE таблицы SALESREPS содержится идентификатор офиса, в котором работает служащий. Доменом этого столбца (множеством значений, которые могут в нем храниться) является множество идентификаторов офисов, содержащихся в столбце OFFICE таблицы OFFICES.

Рисунок 77. Отношение предок/потомок в реляционной
базе данных
То, в каком офисе работает Мэри Джонс (Магу Jones), можно узнать, определив значение столбца REP_OFFICE в строке таблицы SALESREPS для Мэри Джонс (число II) и затем отыскав в таблице OFFICES строку с таким же значением в столбце OFFICE (это для офиса в Нью-Йорке). Таким же образом, чтобы найти всех служащих нью-йоркского офиса, следует запомнить значение столбца OFFICE для Нью-Йорка (число II), а потом просмотреть таблицу SALESREPS и найти все строки, в столбце REP_OFFICE которых содержится число 11 (это строки для Мэри Джонс и Сэма Кларка (Sam Clark)).
Отношение предок/потомок, существующее между офисами и работающими в них людьми, в реляционной модели не потеряно; просто оно реализовано в виде одинаковых значений данных, хранящихся в двух таблицах, а не в виде явного указателя. Все отношения, существующие между таблицами реляционной базы данных, реализуются в таком виде.
Столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом другой таблицы, называется внешним ключом. На рис. 77 столбец REP_OFFICE представляет собой внешний ключ для таблицы OFFICES. Значения, содержащиеся в этом столбце, представляют собой идентификаторы офисов. Эти значения соответствуют значениям в столбце OFFICE, который является первичным ключом таблицы OFFICES. Совокупно первичный и внешний ключи создают между таблицами, в которых они содержатся, такое же отношение предок/потомок, как и в иерархической базе данных.
Внешний ключ, как и первичный ключ, тоже может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей. На рисунке 78 показаны три внешних ключа таблицы ORDERS из учебной базы данных:
· столбец REP является внешним ключом для таблицы SALESREPS исвязывает каждый заказ со служащим, принявшим его;
· столбец CUST является внешним ключом для таблицы CUSTOMES и связывает каждый заказ с клиентом, разместившим его;
· столбцы MRF и PRODUCT совокупно представляют собой составной внешний ключ для таблицы PRODUCTS, который связывает каждый заказ с заказанным товаром.

Рисунок 78. Множественные отношения предок/потомок в реляционной базе данных (отношение многие-ко-многим)
Отношения предок/потомок, созданные с помощью трех внешних ключей в таблице ORDERS, могут показаться знакомыми. И действительно, это те же самые отношения, что и в сетевой базе данных, представленной на рис. 72.
| < Предыдущая | Следующая > |
|---|

